 Ajustes / Pestaña LLM local
Ajustes / Pestaña LLM local
Idioma
- Selecciona tu idioma. Los idiomas admitidos son inglés, español, francés, alemán, ucraniano y ruso.
Modo de conversación (activado/desactivado)
- El "Modo de conversación" te permite chatear con el LLM. Cuando está desactivado (por defecto), el LLM funciona en modo de comando estricto. Solo analizará comandos y ejecutará consultas y acciones, pero ignorará toda entrada sin sentido.
Directorio de diario
- Ubicación del directorio de diario del juego. Así es como Elite Intel conoce tu sesión de juego.
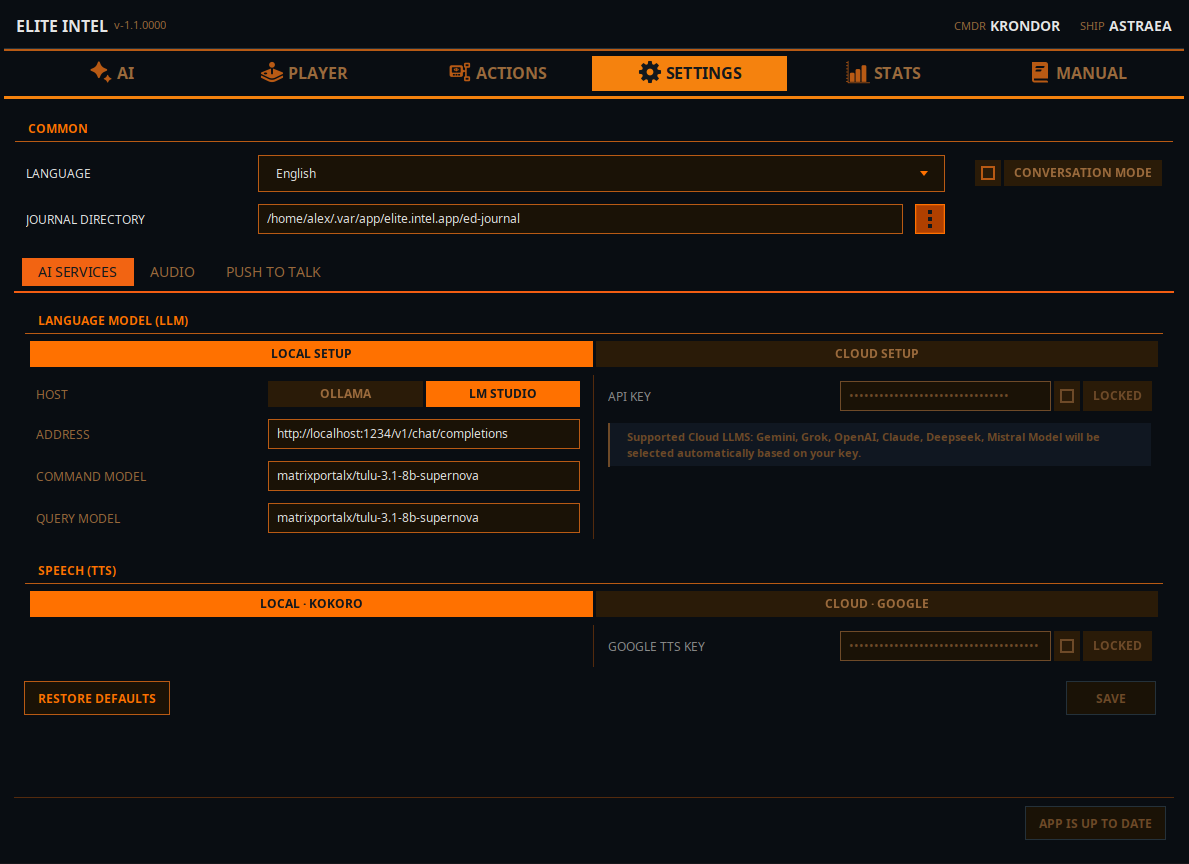
Opciones de LLM
LLM local
- Elige un motor de inferencia. Ollama o LMStudio (opción más rápida)
- En el campo DIRECCIÓN, introduce la dirección de tu servidor de inferencia. Ya sea el host local si lo ejecutas en la misma máquina o la dirección IP del equipo en tu red de área local. Proporciona el número de puerto y la URI para el endpoint de la API.
- Introduce el nombre del modelo en el campo Modelo de comandos. Este será el modelo utilizado para la clasificación de la entrada del usuario.
- Introduce el nombre del modelo en el campo Modelo de consultas. Este será el modelo utilizado para consultas y respuestas en lenguaje natural.
- NOTA: Puedes usar el mismo modelo para ambos, especialmente si no tienes hardware para ejecutar más de un modelo.
LLM en la nube
Si no tienes hardware para ejecutar un LLM local, puedes usar una instancia en la nube.
- Mistral Console tiene un nivel gratuito y es fácil de configurar.
- Alternativamente, puedes usar Claude, Gemini, Grok (xAi), Open AI o DeepSeek. Inicia sesión en la consola de API de tu proveedor de LLM preferido y crea una clave API.
- Introduce la clave en el campo de clave API, bloquea el campo y haz clic en "usar" para indicarle a la app que estás usando un LLM en la nube.
- Reinicia los servicios en la pestaña principal para que los cambios surtan efecto.
NOTA 👉 Ver más sobre LLMs en la nube aquí 👈
 Ajustes / Audio
Ajustes / Audio
Configura tus ajustes de audio.
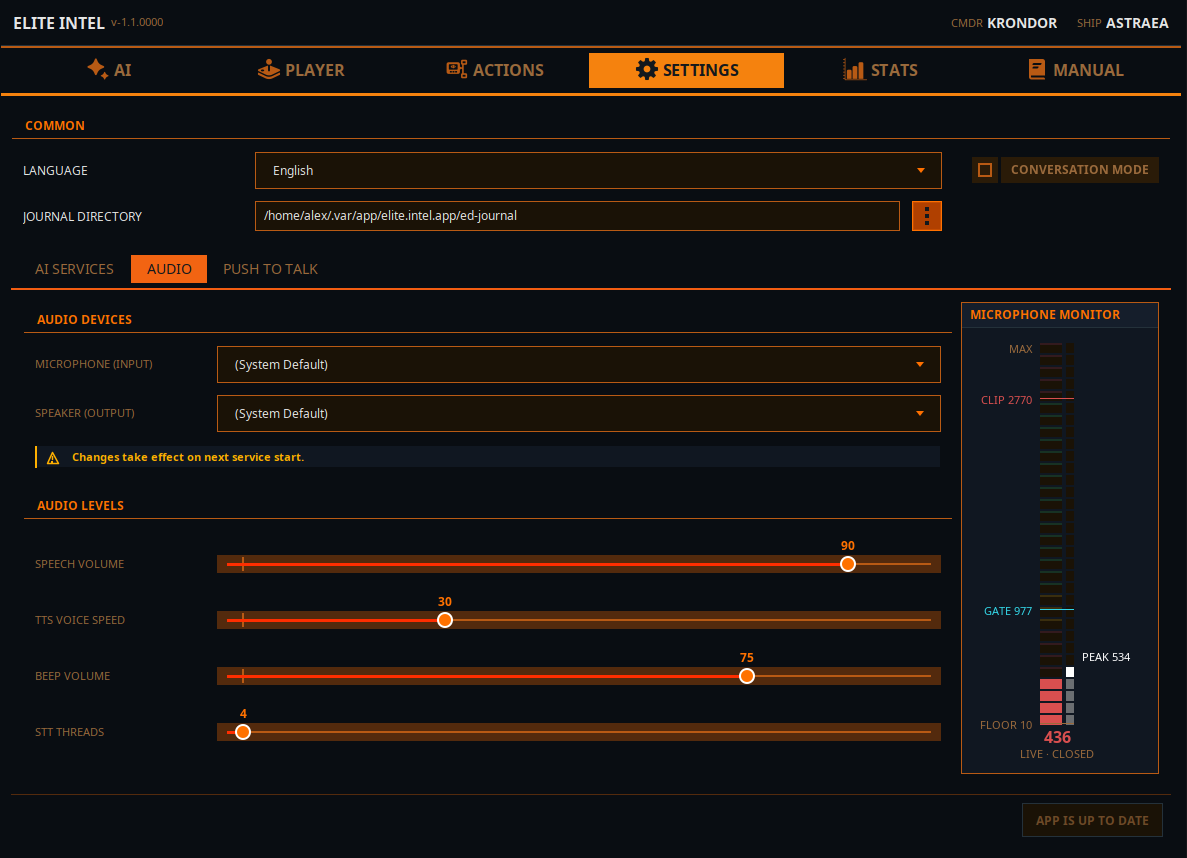
Los menús desplegables de Micrófono y Altavoces te permiten seleccionar las líneas de entrada y salida de audio. El cambio surtirá efecto cuando reinicies los servicios en la pestaña principal.
Volumen de voz: Controla el volumen de la síntesis de voz.
Velocidad de voz TTS: Controla la velocidad de la síntesis de voz.
Volumen del pitido: Controla el volumen del indicador sonoro. Indica que el STT ha terminado de procesar y que el LLM ha recibido la entrada.
Hilos STT: Establece la asignación de hilos para el procesamiento STT. Es un ajuste de mínimo/máximo. La app solicita el mínimo pero usa lo que el procesador proporciona. Los hilos se liberan tras completar el procesamiento.
Monitor de micrófono
Nivel de SUELO (el nivel de ruido cuando no estás hablando),
Nivel de PUERTA, indica el nivel de la puerta de audio. Cuando el audio supera la puerta, los datos se envían a Parakeet para su transcripción. Cuando el audio cae por debajo del nivel de la puerta, el audio recibido se transcribe a texto y se envía al LLM para su clasificación.
RECORTE indica que estás saturando el micrófono si tu entrada supera esa línea. Si lo hace, la transcripción será imprecisa.
 Ajustes / Pulsar para hablar
Ajustes / Pulsar para hablar
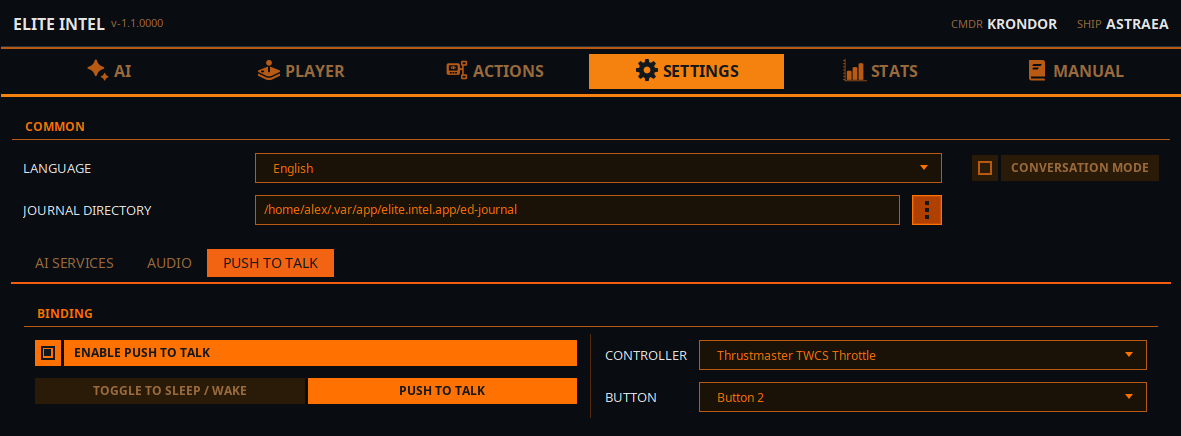
Configurar PPH (Pulsar Para Hablar)
Pulsar para hablar solo funciona con un mando, no con teclado. Sí, tendrías que sacrificar un botón del mando, pero ganarás acceso a más de 200 comandos/consultas.
Los ajustes de PPH tienen dos modos.
- Alternar Reposo/Activo Esta opción simplemente alterna la app entre el modo Reposo y el modo Activo. En modo Reposo, la app ignorará toda tu entrada de voz excepto el comando "Wake Up!". La palabra de activación "listen" o "listen up" anulará el modo de reposo. "Listen up!, Lower the landing gear." pasará igualmente.
- Modo PPH En el modo de Pulsar Para Hablar puro, la app está "dormida" e ignora toda tu entrada. Cuando se mantiene presionado el botón PPH del mando, escucharás un pitido; di tu comando o consulta y suelta el botón. Escucharás otro pitido que indica que tu entrada está siendo procesada.
 Ajustes / Estadísticas
Ajustes / Estadísticas
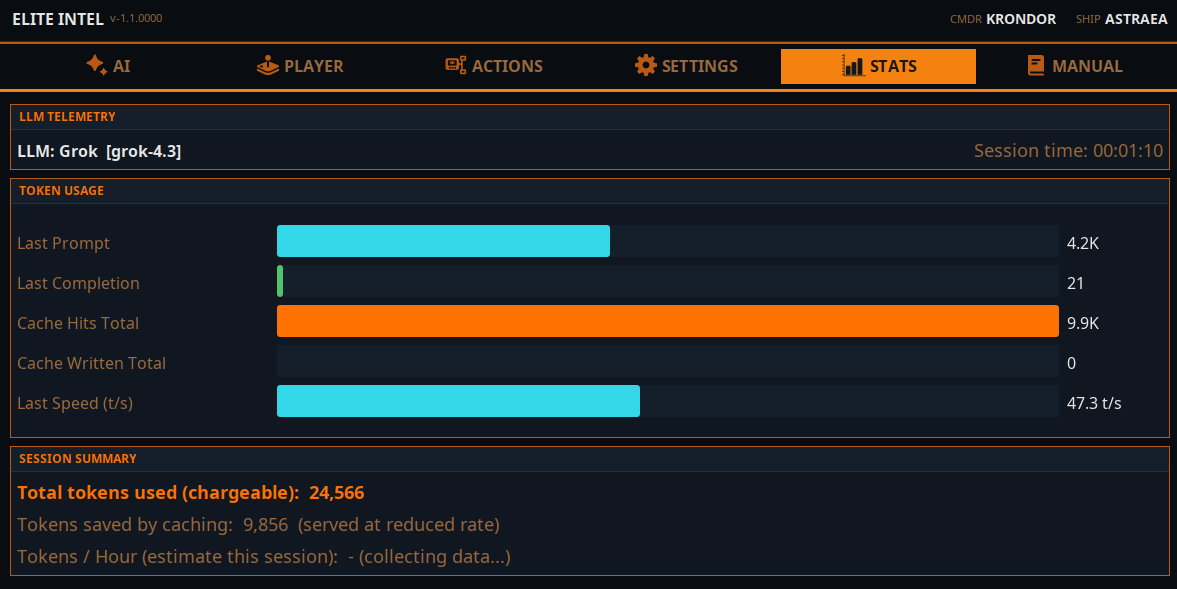
La pestaña de estadísticas muestra el uso de tokens. Los tokens son las unidades básicas de cómputo del LLM. Un token es una sola palabra o número.
La integración con modelos en la nube está ajustada por proveedor para maximizar el almacenamiento en caché de tokens. Los tokens en caché son gratuitos o se facturan a una tarifa menor, dependiendo del proveedor. En promedio, la app usa alrededor de 250 000 tokens por hora en total. Algunos proveedores en la nube pueden almacenar en caché hasta el 80% de ellos, otros alrededor del 40%. Depende de la nube que elijas.
La estimación se mostrará según tu uso una vez que ejecutes tu sesión durante más de 15 minutos. Es un cálculo aproximado.
El LLM local no muestra tokens en caché. Esa información no es relevante para el LLM local.