 Paramètres / Onglet LLM local
Paramètres / Onglet LLM local
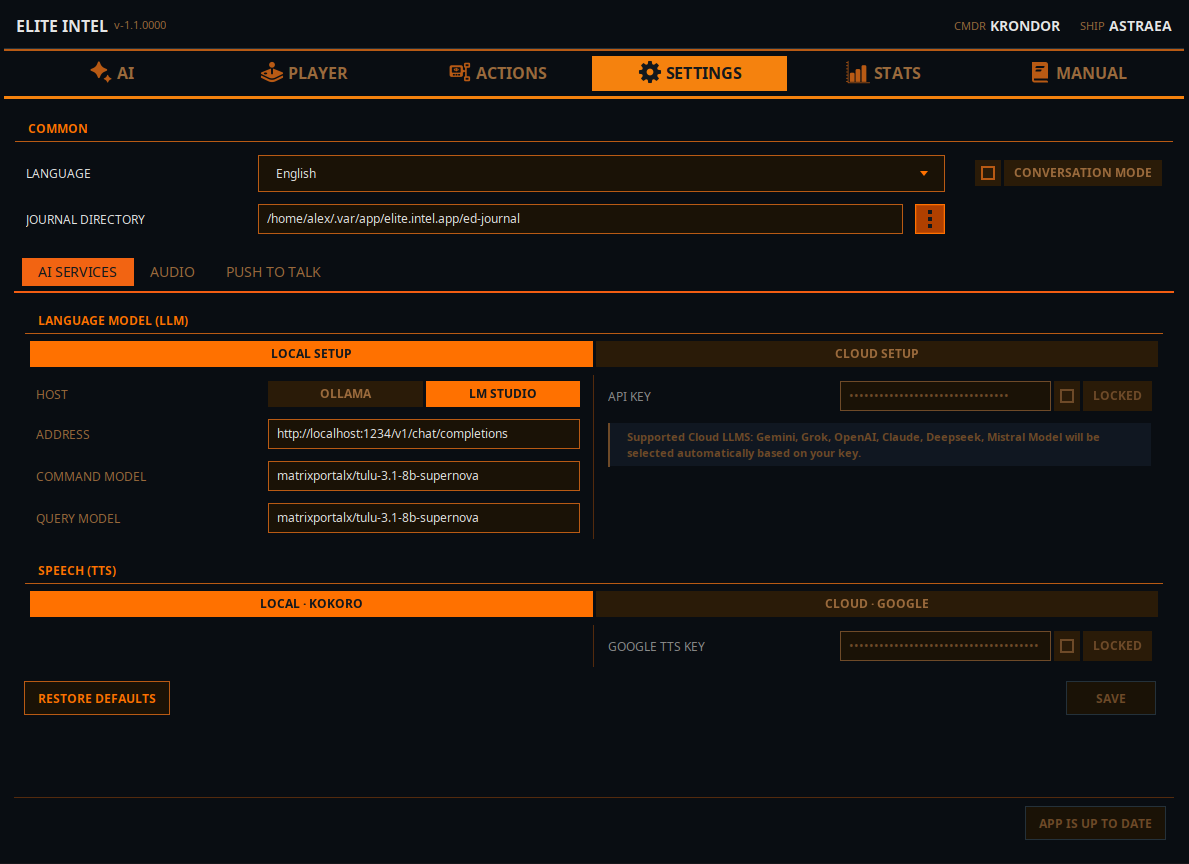
Langue
- Sélectionnez votre langue. Les langues prises en charge sont : anglais, espagnol, français, allemand, ukrainien et russe.
Mode conversation (on/off)
- Le "Mode conversation" vous permet de discuter avec le LLM. Lorsqu'il est désactivé (par défaut), le LLM fonctionne en mode de commande strict. Il analysera uniquement les commandes et effectuera des requêtes et actions, mais ignorera toutes les entrées non pertinentes.
Répertoire des journaux
- Emplacement du répertoire des journaux du jeu. C'est ainsi qu'Elite Intel connaît votre session de jeu.
Options LLM
LLM local
- Choisissez un hôte pour le moteur d'inférence. Ollama ou LMStudio (option plus rapide)
- Dans le champ ADRESSE, entrez l'adresse de votre serveur d'inférence. Soit localhost si vous l'exécutez sur la même machine, soit l'adresse IP de l'ordinateur sur votre réseau local. Indiquez le numéro de port et l'URI du point de terminaison API
- Entrez le nom du modèle dans le champ Modèle de commande. Ce sera le modèle utilisé pour la classification des entrées utilisateur
- Entrez le nom du modèle dans le champ Modèle de requête. Ce sera le modèle utilisé pour les requêtes et les réponses en langage naturel
- NOTE : Vous pouvez utiliser le même modèle pour les deux. Surtout si vous n'avez pas le matériel pour exécuter plus d'un modèle
LLM cloud
Si vous n'avez pas le matériel pour exécuter un LLM local, vous pouvez utiliser une instance cloud à la place.
- Mistral Console propose un niveau gratuit et est facile à configurer
- Vous pouvez également utiliser Claude, Gemini, Grok (xAi), Open AI ou DeepSeek. Connectez-vous à la console API de votre fournisseur de LLM préféré et créez une clé API.
- Entrez la clé dans le champ de clé API, verrouillez le champ et cliquez sur "use" pour indiquer à l'application que vous utilisez un LLM cloud.
- Redémarrez les services dans l'onglet principal pour que les modifications prennent effet.
NOTE 👉 En savoir plus sur les LLMs cloud ici 👈
 Paramètres / Audio
Paramètres / Audio
Configurez vos paramètres audio
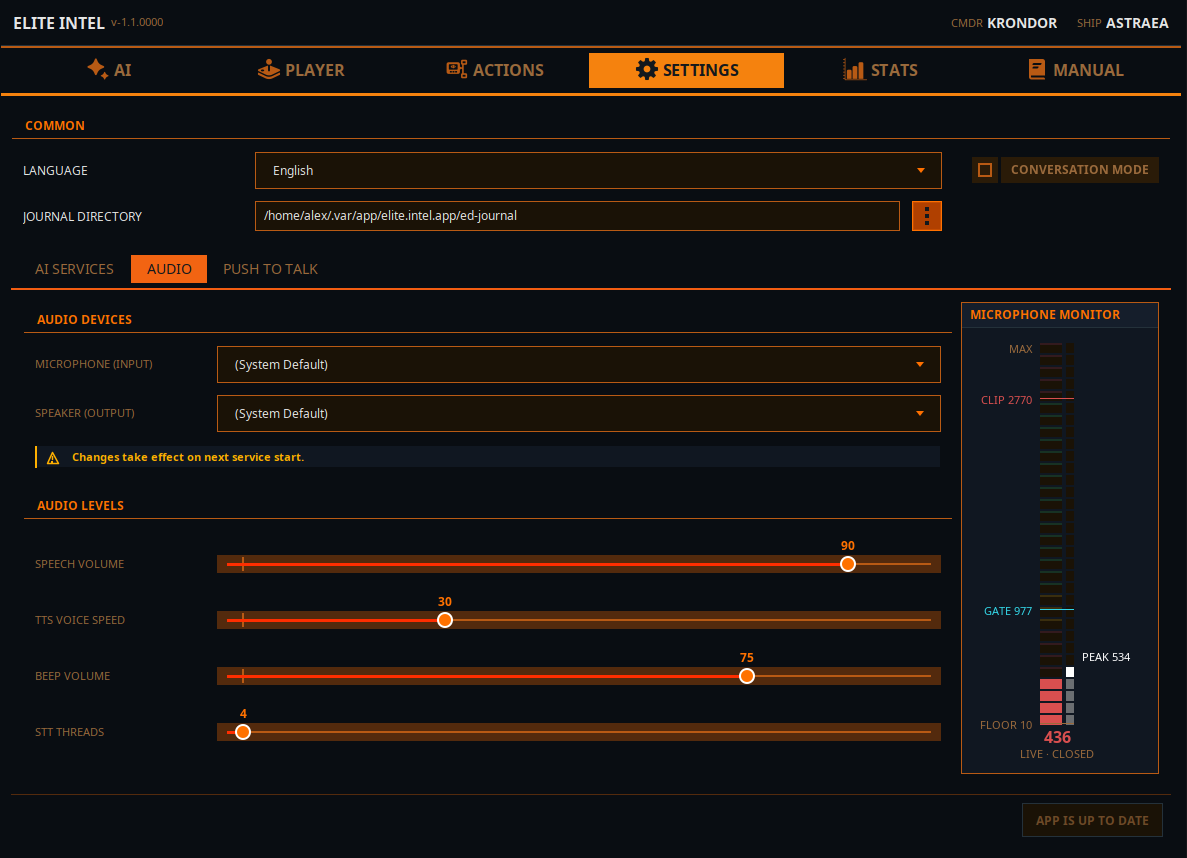
Les listes déroulantes Microphone et Haut-parleurs vous permettent de sélectionner les lignes d'entrée et de sortie audio. Le changement prendra effet lors du redémarrage des services dans l'onglet principal.
Volume de la parole : Contrôle le volume de la synthèse vocale.
Vitesse vocale TTS : Contrôle la vitesse de la synthèse vocale.
Volume du bip : Contrôle le volume de l'indicateur sonore. Indique que le STT a terminé le traitement et que le LLM a reçu l'entrée.
Threads STT : Définit l'allocation de threads pour le traitement STT. Il s'agit d'un paramètre min/max. L'application demande le minimum mais utilise ce que le processeur fournit. Les threads sont libérés une fois le traitement terminé.
Moniteur de microphone
Niveau PLANCHER (le niveau de bruit lorsque vous ne parlez pas),
Niveau GATE, indique le niveau du seuil audio. Lorsque le son est au-dessus du seuil, les données sont envoyées à Parakeet pour transcription. Lorsque le son passe en dessous du seuil, l'audio reçu est transcrit en texte et envoyé au LLM pour classification
CLIP indique que vous saturez le micro si votre entrée dépasse cette ligne. Si c'est le cas, la transcription sera imprécise.
 Paramètres / Push To Talk
Paramètres / Push To Talk
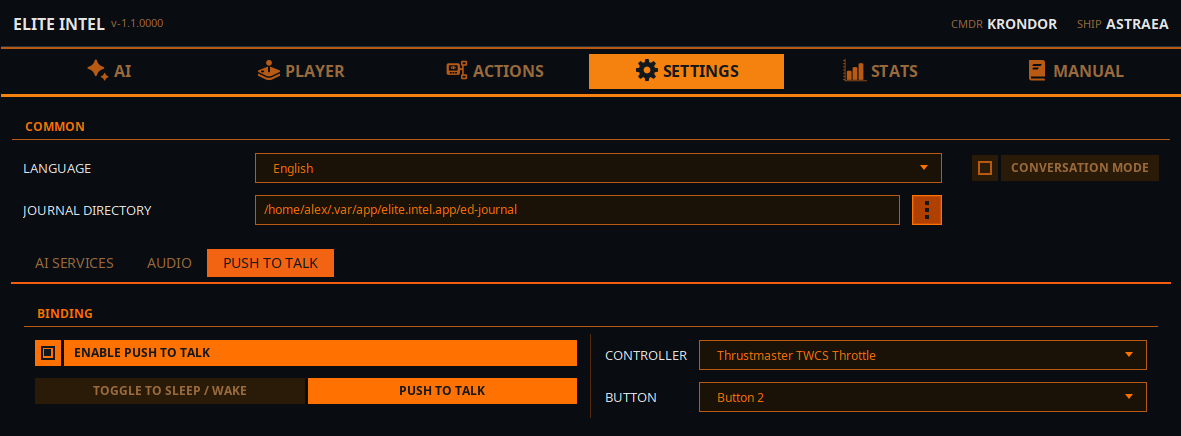
Configurer le PTT (Push To Talk)
Le Push To Talk ne fonctionne qu'avec un contrôleur, pas avec un clavier. Oui, vous devrez sacrifier un bouton sur votre contrôleur, mais vous aurez accès à plus de 200 commandes/requêtes.
Les paramètres PTT ont deux modes.
- Basculer Veille/Réveil Cette option bascule simplement l'application entre les modes Veille et Réveil. En mode Veille, l'application ignorera toutes vos entrées vocales sauf la commande "Wake Up!". Le mot de contournement "listen" ou "listen up" permettra de passer outre le mode veille. "Listen up!, Lower the landing gear." passera quand même
- Mode PTT En mode Push To Talk pur, l'application est "en veille" et ignore toutes vos entrées. Lorsque le bouton PTT du contrôleur est pressé et maintenu, vous entendrez un bip, dites votre commande ou requête et relâchez le bouton. Vous entendrez un autre bip indiquant que votre entrée est en cours de traitement.
 Paramètres / Statistiques
Paramètres / Statistiques
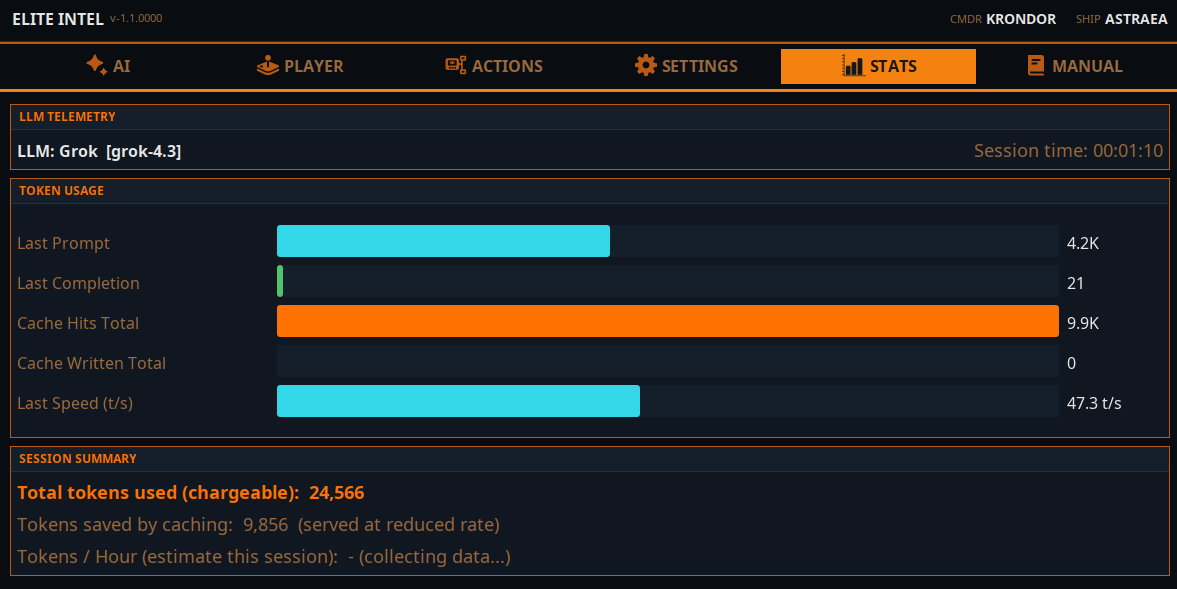
L'onglet statistiques vous indique votre consommation de tokens. Les tokens sont les unités de base du calcul LLM. Un token est un seul mot ou nombre.
L'intégration du modèle cloud est optimisée par fournisseur pour maximiser la mise en cache des tokens. Les tokens mis en cache sont soit gratuits, soit facturés à un tarif réduit. Cela dépend du fournisseur. En moyenne, l'application utilise environ 250 000 tokens par heure au total. Certains fournisseurs cloud peuvent en mettre en cache jusqu'à 80%, d'autres environ 40%. Cela dépend du cloud que vous choisissez.
L'estimation sera affichée en fonction de votre utilisation une fois que vous aurez joué pendant plus de 15 minutes. Il s'agit d'un calcul approximatif.
Le LLM local n'affiche pas les tokens mis en cache. Cette information n'est pas pertinente pour le LLM local.