 Налаштування / Вкладка локального LLM
Налаштування / Вкладка локального LLM
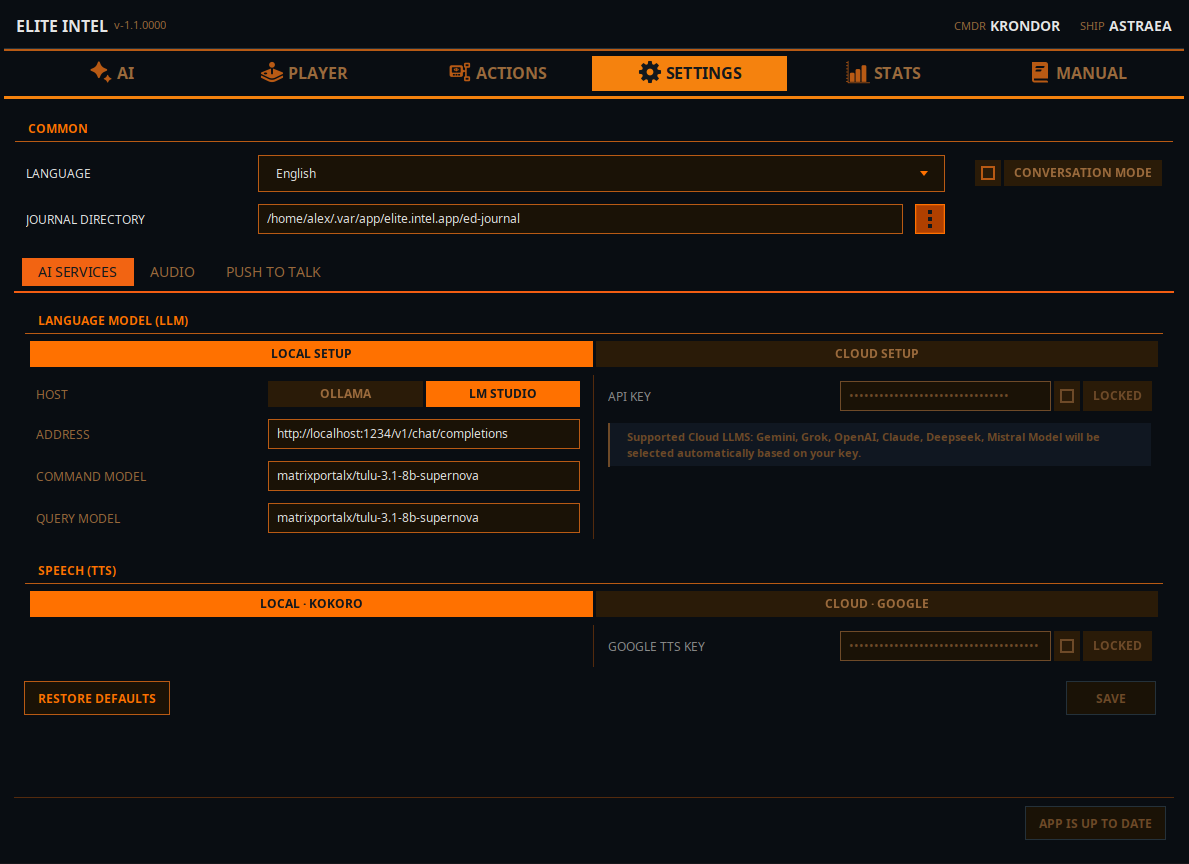
Мова
- Оберіть вашу мову. Підтримувані мови: англійська, іспанська, французька, німецька, українська та російська.
Режим розмови (увімк./вимк.)
- «Режим розмови» дозволяє вам вести чат із LLM. Коли вимкнений (за замовчуванням), LLM працює у суворому режимі команд. Він лише розбиратиме команди та виконуватиме запити й дії, але ігнорує будь-яке безглузде введення.
Каталог журналу
- Розташування каталогу журналу вашої гри. Саме так Elite Intel знає про вашу ігрову сесію.
Параметри LLM
Локальний LLM
- Оберіть хост механізму виводу. Ollama або LMStudio (швидший варіант)
- У полі ADDRESS введіть адресу вашого сервера виводу. Або localhost, якщо він запущений на тому самому комп'ютері, або IP-адресу комп'ютера у вашій локальній мережі. Вкажіть номер порту та URI для кінцевої точки API
- Введіть назву моделі в полі Command Model. Ця модель буде використовуватись для класифікації введення користувача
- Введіть назву моделі в полі Query Model. Ця модель буде використовуватись для запитів та відповідей природною мовою
- ПРИМІТКА: Ви можете використовувати одну й ту саму модель для обох. Особливо якщо у вас немає заліза для запуску більше ніж однієї моделі
Хмарний LLM
Якщо у вас немає заліза для запуску локального LLM, натомість можна використовувати хмарний екземпляр.
- Mistral Console має безкоштовний рівень і легко налаштовується
- Альтернативно, ви можете використовувати Claude, Gemini, Grok (xAi), Open AI або DeepSeek. Увійдіть до API-консолі вашого постачальника LLM на вибір і створіть API-ключ.
- Введіть ключ у поле API key, заблокуйте поле та натисніть «use», щоб повідомити застосунку, що ви використовуєте хмарний LLM.
- Перезапустіть сервіси на вкладці AI, щоб зміни набули чинності.
ПРИМІТКА 👉 Докладніше про хмарні LLM тут 👈
 Налаштування / Аудіо
Налаштування / Аудіо
Налаштуйте параметри аудіо
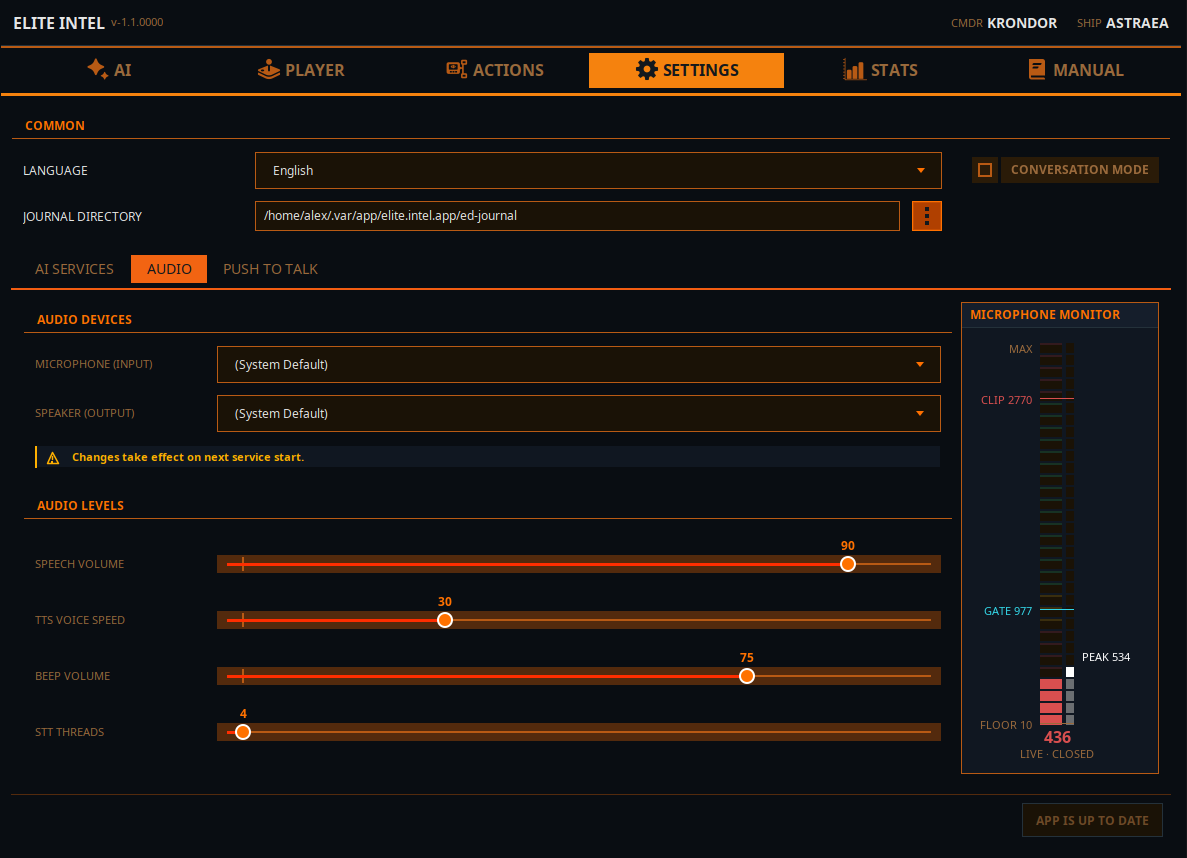
Спадні меню Мікрофон і Динаміки дозволяють вибрати лінії аудіовведення та виведення. Зміна набуде чинності після перезапуску сервісів на вкладці AI.
Speech Volume: Керує гучністю синтезу мовлення.
TTS Voice Speed: Керує швидкістю синтезу мовлення.
Beep Volume: Керує гучністю звукового індикатора. Вказує, що STT завершив обробку і LLM отримав введення.
STT Threads: Встановлює виділення потоків для обробки STT. Це параметр мін./макс. Застосунок запитує мінімум, але використовує те, що надає процесор. Потоки звільняються після завершення обробки.
Microphone Monitor
Рівень FLOOR (рівень шуму, коли ви не говорите),
Рівень GATE вказує рівень аудіошлюзу. Коли аудіо перевищує шлюз, дані надсилаються до Parakeet для транскрипції. Коли аудіо падає нижче рівня шлюзу, отримане аудіо транскрибується в текст і надсилається до LLM для класифікації
CLIP вказує, що ви перевантажуєте мікрофон, якщо ваш сигнал перевищує цю лінію. Якщо це відбувається, транскрипція буде неточною.
 Налаштування / Push To Talk
Налаштування / Push To Talk
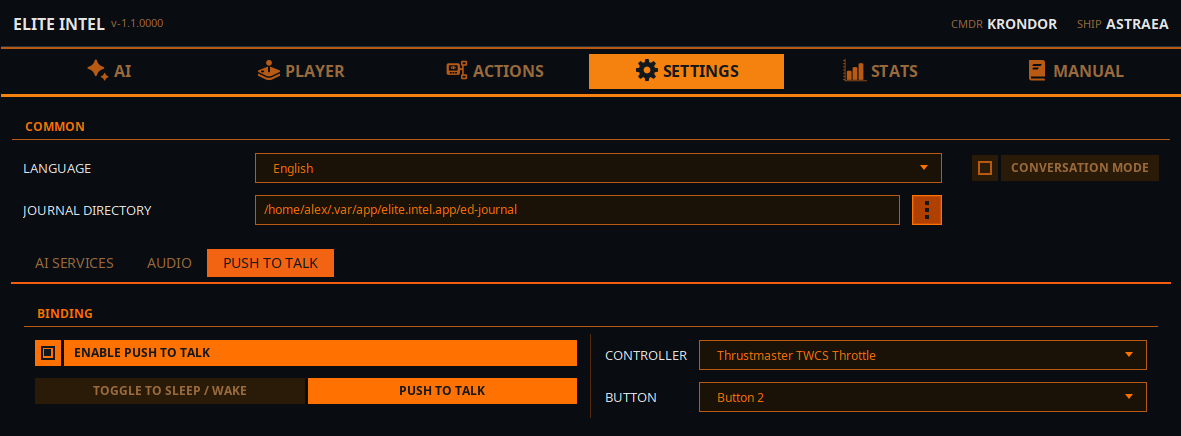
Налаштування PTT (Push To Talk)
Push To Talk працює лише з контролером, а не з клавіатурою. Так, доведеться пожертвувати кнопкою на контролері, але натомість ви отримаєте доступ до понад 200 команд/запитів.
Налаштування PTT мають два режими.
- Toggle Sleep/Wake Цей варіант просто перемикає застосунок між режимами сну та пробудження. У режимі сну застосунок ігнорує весь ваш голосовий ввід, окрім команди «Wake Up!». Обхідне слово «listen» або «listen up» обходить режим сну. «Listen up!, Lower the landing gear.» пройде.
- PTT Mode У чистому режимі Push To Talk застосунок «спить» і ігнорує весь ваш ввід. Коли кнопка PTT на контролері натиснута й утримується, ви почуєте звуковий сигнал, скажіть команду або запит і відпустіть кнопку. Ви почуєте інший звуковий сигнал, що вказує на те, що ваш ввід обробляється.
 Налаштування / Статистика
Налаштування / Статистика
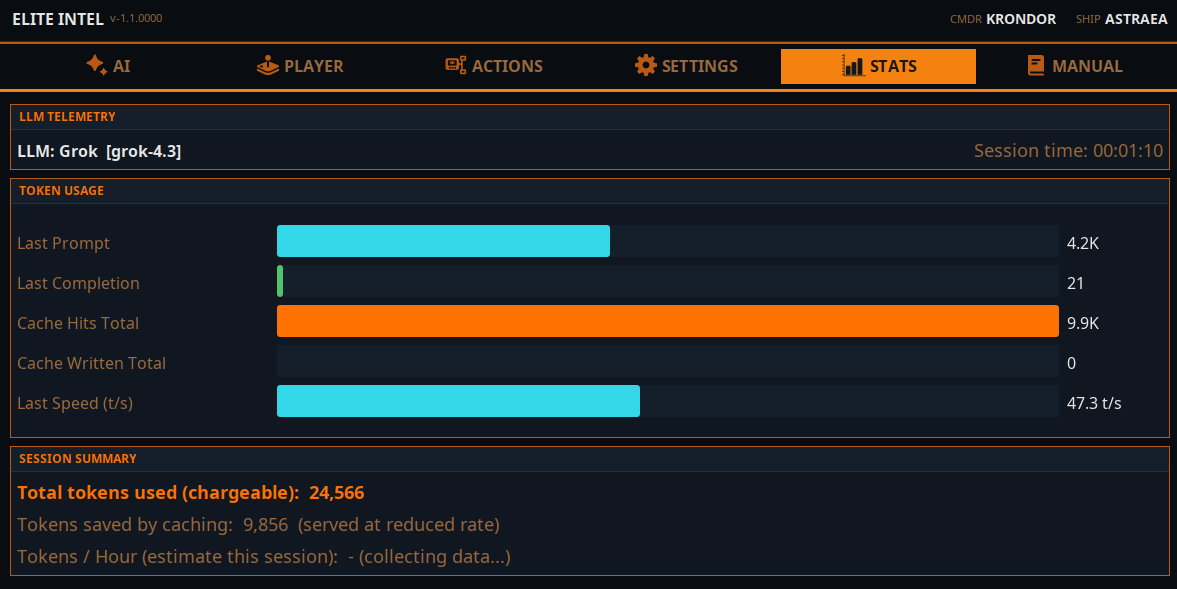
На вкладці статистики показано використання токенів. Токени базові одиниці обчислень LLM. Токен це одне слово або число.
Інтеграція хмарних моделей налаштована для кожного постачальника для максимального кешування токенів. Кешовані токени або безкоштовні, або оплачуються за нижчою ставкою. Це залежить від постачальника. В середньому застосунок використовує приблизно 250 тисяч токенів на годину загалом. Деякі хмарні постачальники можуть кешувати до 80% з них, інші близько 40%. Залежить від обраної хмари.
Оцінка буде показана на основі вашого використання після того, як ви запустите сесію більш ніж на 15 хвилин. Це приблизний розрахунок.
Локальний LLM не відображає кешовані токени. Ця інформація не актуальна для локального LLM.