 Einstellungen / Lokaler LLM-Tab
Einstellungen / Lokaler LLM-Tab
Sprache
- Wähle deine Sprache. Unterstützte Sprachen sind Englisch, Spanisch, Französisch, Deutsch, Ukrainisch und Russisch.
Konversationsmodus (an/aus)
- Der „Konversationsmodus" ermöglicht es dir, mit dem LLM zu chatten. Wenn er ausgeschaltet ist (Standard), läuft das LLM im strikten Befehlsmodus. Es verarbeitet nur Befehle und führt Abfragen und Aktionen durch, ignoriert jedoch alle sinnlosen Eingaben.
Journal-Verzeichnis
- Speicherort deines Spiel-Journal-Verzeichnisses. Darüber erkennt Elite Intel deine Spielsitzung.
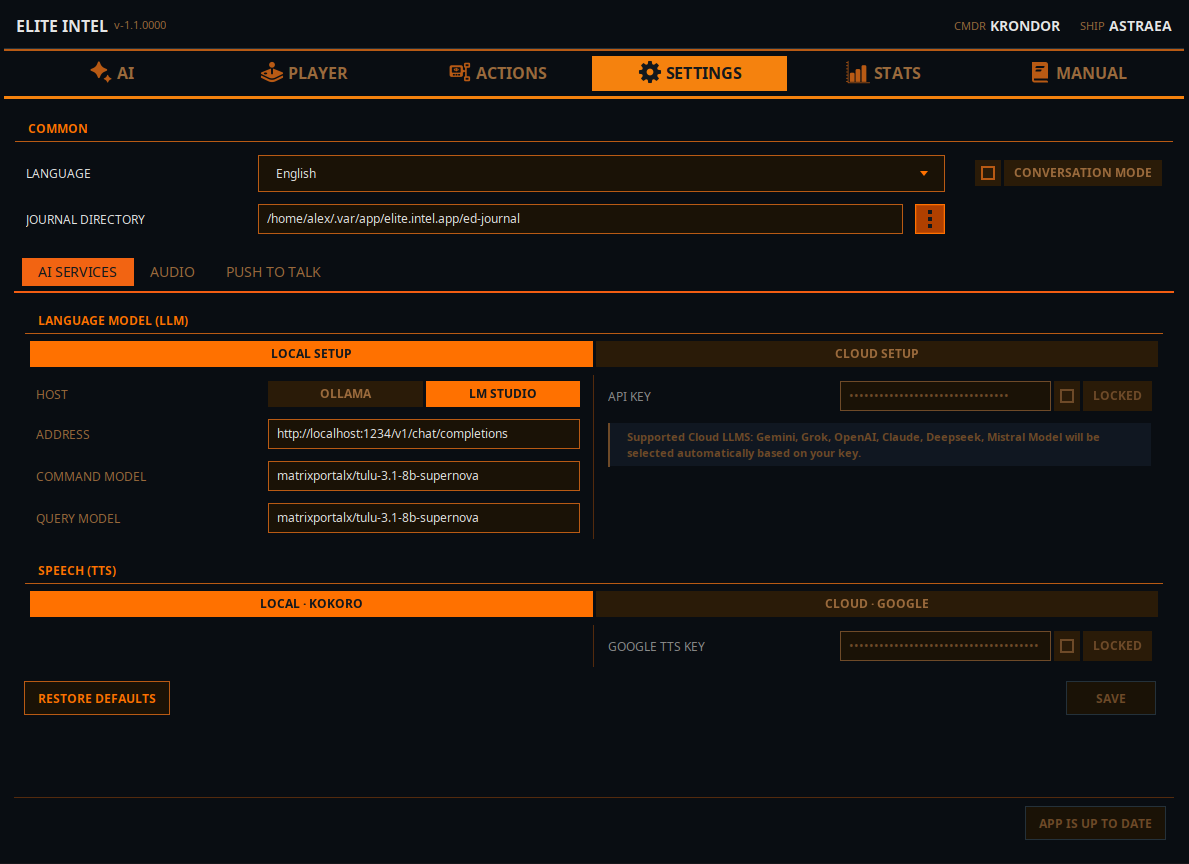
LLM-Optionen
Lokales LLM
- Wähle einen Inferenz-Engine-Host. Ollama oder LMStudio (schnellere Option)
- Gib im Feld ADRESSE die Adresse deines Inferenzservers ein. Entweder localhost, wenn du ihn auf demselben Rechner betreibst, oder eine IP-Adresse des Computers in deinem lokalen Netzwerk. Gib Portnummer und URI für den API-Endpunkt an.
- Gib den Namen des Modells im Feld „Befehls-Modell" ein. Dieses Modell wird für die Klassifizierung der Benutzereingabe verwendet.
- Gib den Namen des Modells im Feld „Abfrage-Modell" ein. Dieses Modell wird für Abfragen und natürlichsprachliche Antworten verwendet.
- HINWEIS: Du kannst dasselbe Modell für beides verwenden, besonders wenn du keine Hardware hast, um mehr als ein Modell zu betreiben.
Cloud-LLM
Wenn du keine Hardware für ein lokales LLM hast, kannst du stattdessen eine Cloud-Instanz verwenden.
- Mistral Console hat einen kostenlosen Tarif und ist einfach einzurichten.
- Alternativ kannst du Claude, Gemini, Grok (xAi), Open AI oder DeepSeek verwenden. Melde dich bei der API-Konsole deines bevorzugten LLM-Anbieters an und erstelle einen API-Schlüssel.
- Gib den Schlüssel in das API-Schlüssel-Feld ein, sperr das Feld und klicke auf „Verwenden", damit die App weiß, dass du ein Cloud-LLM nutzt.
- Starte die Dienste im vorderen Tab neu, damit die Änderungen wirksam werden.
HINWEIS 👉 Mehr zu Cloud-LLMs hier 👈
 Einstellungen / Audio
Einstellungen / Audio
Konfiguriere deine Audioeinstellungen.
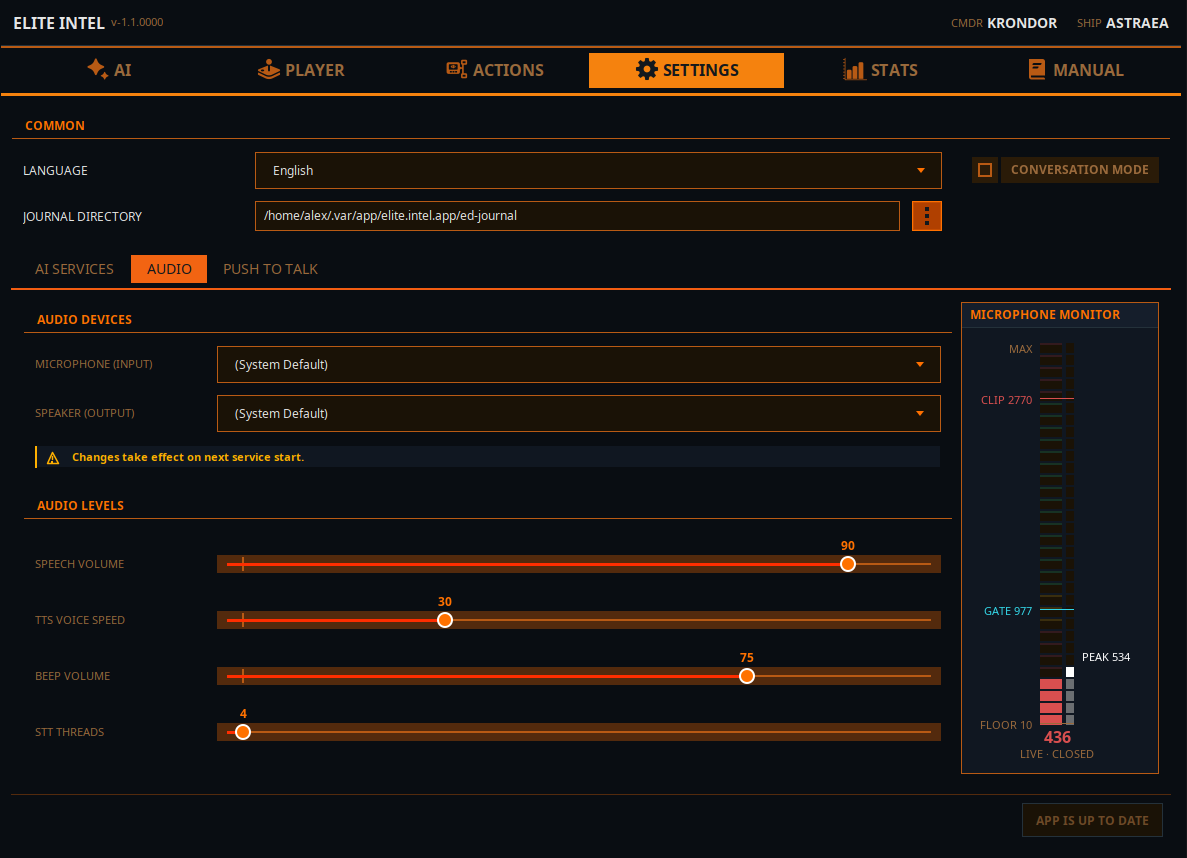
Die Dropdown-Menüs Mikrofon und Lautsprecher ermöglichen die Auswahl der Audio-Ein- und Ausgabeleitungen. Die Änderung wird wirksam, wenn du die Dienste im vorderen Tab neu startest.
Sprachlautstärke: Steuert die Lautstärke der Sprachsynthese.
TTS-Sprechgeschwindigkeit: Steuert die Geschwindigkeit der Sprachsynthese.
Piepton-Lautstärke: Steuert die Lautstärke des Piepton-Indikators. Zeigt an, dass STT die Verarbeitung abgeschlossen hat und der LLM die Eingabe erhalten hat.
STT-Threads: Legt die Thread-Zuweisung für die STT-Verarbeitung fest. Dies ist eine Min/Max-Einstellung. Die App fordert das Minimum an, nutzt aber was der Prozessor bereitstellt. Threads werden nach Abschluss der Verarbeitung freigegeben.
Mikrofon-Monitor
FLOOR-Pegel (der Geräuschpegel, wenn du nicht sprichst),
GATE-Pegel, zeigt den Audio-Gate-Pegel an. Wenn Audio über dem Gate liegt, werden die Daten zur Transkription an Parakeet gesendet. Wenn der Audiopegel unter den Gate-Pegel fällt, wird das empfangene Audio in Text umgewandelt und zur Klassifizierung an das LLM gesendet.
CLIP zeigt an, dass du das Mikrofon übersteuert, wenn deine Eingabe diese Linie überschreitet. In diesem Fall wird die Transkription ungenau.
 Einstellungen / Push To Talk
Einstellungen / Push To Talk
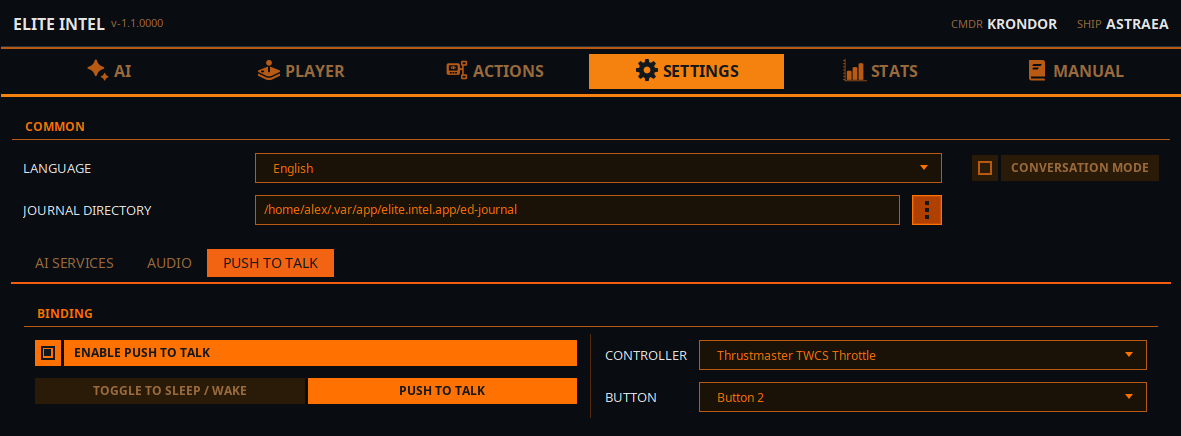
PTT (Push To Talk) konfigurieren
Push To Talk funktioniert nur mit einem Controller, nicht mit einer Tastatur. Ja, du musst einen Knopf deines Controllers opfern, erhältst aber Zugang zu über 200 Befehlen/Abfragen.
PTT-Einstellungen haben zwei Modi.
- Schlaf/Wach umschalten Diese Option schaltet die App einfach zwischen Schlaf- und Wachmodus um. Im Schlafmodus ignoriert die App alle Spracheingaben außer dem Befehl „Wake Up!". Das Umgehungswort „listen" oder „listen up" umgeht den Schlafmodus. „Listen up!, Lower the landing gear." wird durchgeleitet.
- PTT-Modus Im reinen Push-To-Talk-Modus „schläft" die App und ignoriert alle Eingaben. Wenn der PTT-Knopf auf dem Controller gedrückt und gehalten wird, ertönt ein Piepton. Sag deinen Befehl oder deine Abfrage und lass den Knopf los. Ein weiterer Piepton zeigt an, dass deine Eingabe verarbeitet wird.
 Einstellungen / Statistiken
Einstellungen / Statistiken
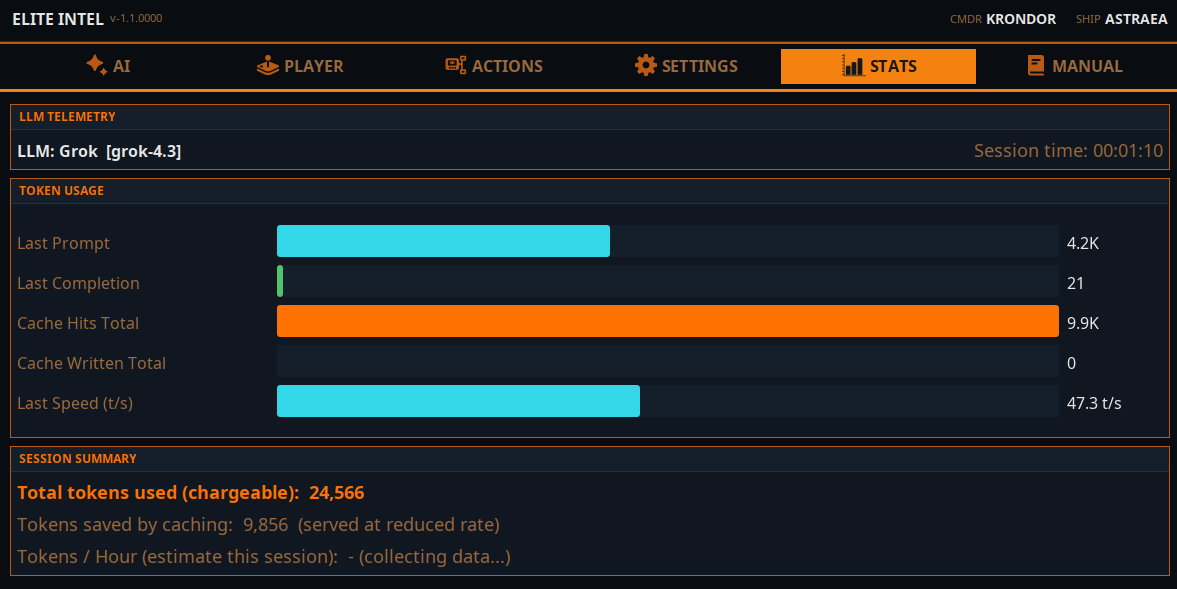
Der Statistik-Tab zeigt dir deinen Token-Verbrauch. Token sind grundlegende Einheiten der LLM-Berechnung. Ein Token entspricht einem einzelnen Wort oder einer Zahl.
Die Cloud-Modell-Integration ist pro Anbieter für maximales Token-Caching optimiert. Gecachte Token sind entweder kostenlos oder werden zu einem niedrigeren Satz abgerechnet. Dies hängt vom Anbieter ab. Im Durchschnitt verbraucht die App rund 250.000 Token pro Stunde insgesamt. Einige Cloud-Anbieter können bis zu 80 % davon cachen, andere etwa 40 %. Dies hängt von der gewählten Cloud ab.
Die Schätzung wird auf Basis deiner Nutzung angezeigt, sobald deine Sitzung länger als 15 Minuten läuft. Es handelt sich um eine ungefähre Berechnung.
Lokale LLMs zeigen keine gecachten Token an. Diese Information ist für lokale LLMs nicht relevant.